
Melhorando a Performance de Consultas no Totvs Protheus – Parte 2

Fala pessoal,
Estamos aqui para o segundo post da nossa série que tem um episódio novo a cada semana.
Antes de lerem esse post, sugiro verem o anterior para que sigam a sequência correta da série:
Agora que já sabem do que se trata essa série de posts, vamos para a análise da nossa próxima query.
Novamente olhando o Trace que monitora as queries mais demoradas do ambiente, essa query abaixo apareceu várias vezes consumindo muitos recursos e demorando mais de 1 minuto:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SELECT R_E_C_N_O_ , D_E_L_E_T_ , CT2_FILIAL FROM dbo.CT2040 WHERE CT2_FILIAL > '01' AND D_E_L_E_T_ = ' ' AND ( CT2_DATA >= '20170101' AND ( ( CT2_DEBITO = '654654654565 ' ) OR ( CT2_CREDIT = '98798798798797 ' ) ) ) ORDER BY CT2_FILIAL , CT2_DATA , CT2_LOTE , CT2_SBLOTE , CT2_DOC , CT2_LINHA , CT2_TPSALD , CT2_EMPORI , CT2_FILORI , CT2_MOEDLC , R_E_C_N_O_; |
Esse é o plano da query:
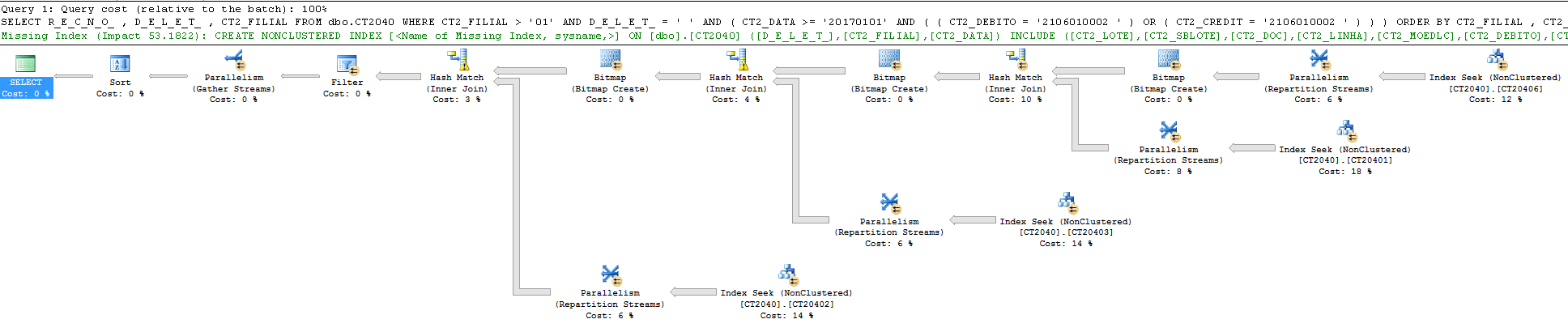
Mais uma vez, todos os índices dessa tabela começam com CT2_FILIAL.
No caso dessa query, o SQL está usando 4 índices para chegar no resultado.
Fabrício, mais uma vez o SQL Server sugeriu um índice. Ser DBA SQL Server é muito fácil. Vamos criar!!!
|
1 2 3 |
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[CT2040] ([D_E_L_E_T_],[CT2_FILIAL],[CT2_DATA]) INCLUDE ([CT2_LOTE],[CT2_SBLOTE],[CT2_DOC],[CT2_LINHA],[CT2_MOEDLC],[CT2_DEBITO],[CT2_CREDIT],[CT2_EMPORI],[CT2_FILORI],[CT2_TPSALD],[R_E_C_N_O_]) |
É aqui que começamos a diferenciar o profissional que entende como os índices funcionam do profissional que caiu de paraquedas nessa análise e não tem interesse em aprender.
D_E_L_E_T_ é uma coluna que tem apenas dois valores distintos (‘*’ ou ”), ou seja, uma péssima coluna para índice, pois não é nada seletiva.
Além disso, a tabela tem quase 30 milhões de registros. Um índice com todas essas colunas vai ficar bem grande.
Vamos tentar outras possibilidades menos traumáticas.
Vamos focar nos filtros da query:
|
1 2 3 4 5 6 7 8 |
WHERE CT2_FILIAL > '01' AND D_E_L_E_T_ = ' ' AND ( CT2_DATA >= '20170101' AND ( ( CT2_DEBITO = '654654654565 ' ) OR ( CT2_CREDIT = '98798798798797 ' ) ) ) |
- CT2_FILIAL e D_E_L_E_T_ não filtram nada, ou seja, não são colunas boas para índices.
- CT2_DATA filtra muito pouco, pois é bem provável que teremos muitos registros em 2017.
- A solução para a query está em CT2_DEBITO e CT2_CREDIT.
Mas Fabrício, agora deu ruim. Tem um miserável de um OR ai nessa query. Já me falaram que OR mata a performance de uma query.
Pois é… Vamos lá…
Realmente OR no WHERE não é legal. Mas é um ERP, se for query padrão não vamos conseguir mudar o código. Temos que sobreviver com esse OR ai mesmo.
Uma coisa que podemos fazer é usar um negócio chamado Index Intersection. Vamos criar um índice em cada coluna do OR e ver se o SQL Server vai usar os dois índices separados, juntar os dois e dar o resultado da query.
|
1 2 3 |
create nonclustered index CT2040W01 on CT2040 (CT2_DEBITO ) with(FILLFACTOR=90,DATA_COMPRESSION=PAGE) create nonclustered index CT2040W02 on CT2040 (CT2_CREDIT ) with(FILLFACTOR=90,DATA_COMPRESSION=PAGE) |
Os dois índices ficaram com um tamanho de 500 MB. Imagina o índice sugerido com todas aquelas colunas.
WOW!!!! Ao rodar a query novamente ela passa a rodar de forma instantânea:
Esse é o novo plano:
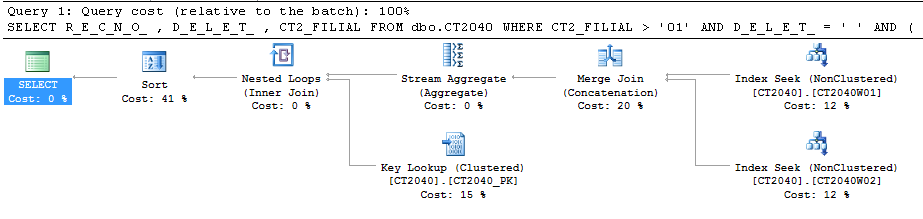
SQL faz um seek nos meus dois índices e depois um Merge Join.
Incluindo todas as colunas usadas na query em um desses índices eu poderia evitar o Key Lookup, mas como a query já passou de 1 minuto e 30 segundos para 0 segundos, vale a pena fazer isso?
Consumo da query antes do índice:
|
1 2 3 4 |
Table 'CT2040'. Scan count 12, logical reads 263520 SQL Server Execution Times: CPU time = 167669 ms, elapsed time = 89505 ms. |
Consumo da query depois do índice:
|
1 2 3 4 |
Table 'CT2040'. Scan count 2, logical reads 3336 SQL Server Execution Times: CPU time = 31 ms, elapsed time = 197 ms. |
Diferença absurda!!!
Antes o SQL Server tinha que ler 263 mil páginas de 8 kb para dar o resultado dessa query. Após o índice ele precisa ler apenas 3 mil páginas para dar o mesmo resultado. Essas páginas tem que passar pela memória, então, antes de comprar mais memória para um servidor, crie alguns índices que o resultado pode ser o mesmo.
Olhando no Trace de queries demoradas, a query ficou tão rápida que tenho que apelar e colocar um waitfor delay para poder visualizar e comparar:

Ela rodou em 0,5 segundos e a diferença de leituras de páginas (263 mil para 3 mil) e do consumo de CPU (176 mil para 31) é gigante!!!
É isso ai pessoal, melhoramos mais uma query no Protheus.
Até a próxima análise de query.
Atualizado no dia 07/10/2020:
Publiquei um curso com 11 horas de duração com toda minha experiência de anos no assunto e de dezenas de clientes Protheus atendidos:
Curso: Melhorando a Performance de Consultas no Totvs Protheus
Gravei uma aula grátis com 60 minutos de duração sobre o que você deve aprender para melhorar a performance no Protheus:
Gostou desse Post?
Curta, comente, compartilhe com os coleguinhas…
Assine meu canal no Youtube e curta minha Página no Facebook para receber Dicas de Leituras e Eventos sobre SQL Server.
Abraços,
Fabrício Lima
Microsoft Data Platform MVP
Consultor e Instrutor SQL Server
Trabalha com SQL Server desde 2006
Essa série tá massa, Fabrício!
Muito didática e simples, dando a visão correta de como utilizar as ferramentas que temos à disposição no SQL Server.
Não trabalho com clientes TOTVS, mas isso se aplica a muitos casos que já vi no meu dia a dia com outros ERPs. As consultas às vezes poderiam ser melhoradas, sem dúvida, mas nem sempre isso é fácil de se conseguir. Então cabe ao DBA contornar esses gargalos de alguma forma.
Parabéns mais uma vez pelo excelente trabalho!
Show. Obrigado Laércio.
Isso aí. A série usa como exemplo um Protheus mas vale para qualquer tipo de banco de dados.
Parabéns, uma explicação e exemplo PRÁTICOS e com comparativos ! Ótimo Trabalho !
Obrigado pelo feedback.
Fabricio, qual tipo de trace vc usou pra identificar as consultas lentas ? Pf, Grato.
Olá Alex,
Da uma olhada nos dois links abaixo:
https://www.fabriciolima.net/blog/2010/06/05/passo-a-passo-para-encontrar-as-querys-mais-demoradas-do-banco-de-dados-parte-1/
https://www.fabriciolima.net/blog/2010/06/05/passo-a-passo-para-encontrar-as-querys-mais-demoradas-do-banco-de-dados-parte-2/
Abraço,
Fabrício
Como obtenho as informações abaixo?
Table ‘CT2040’. Scan count 12, logical reads 263520
SQL Server Execution Times:
CPU time = 167669 ms, elapsed time = 89505 ms.
Table ‘CT2040’. Scan count 12, logical reads 263520
SQL Server Execution Times:
CPU time = 167669 ms, elapsed time = 89505 ms.
Olá Junior,
Basta executar o comando abaixo uma vez na sessão para deixar a opção habilitada (somente nessa sessão). Depois disso, quando você executar algum comando ele irá retornar as informações.
SET STATISTICS IO, TIME ON
Abraço,
Fabrício
Eu posso criar indices no protheus fora do configurador? ele vai acusar erro em indice unico depois ?
Pode ter indices direto no banco sim, mas com nomenclatura diferente da do protheus para nao conflitar.